Correcting Player Positions
NHL clubs will commonly ice a roster consisting of 18 skaters; 4 lines from 12 forwards F and 3 pairs of defenders D. A Center C, Left Wing LW, and Right Wing RW form a line. Left Defence LD and Right Defence RD form a pair. During the even strength portions of a game a team will have 5 skaters on the ice. Predominantly one from each position. While some teams opt to tinker with this set up, we expect the total number of C, LW and RW games played to be balanced. For the 2021/2022 regular season we see this is not the case.
| Position | Counts | % |
|---|---|---|
| D | 15903 | 0.336871 |
| C | 15794 | 0.334562 |
| LW | 9096 | 0.192679 |
| RW | 6415 | 0.135888 |
Positions are hardly ever updated once a player joins the league. This leads to some untrustworthy situations. Consider the game between the Ducks and Hawks on March 23rd 2022 (gameId: 2021021018). By the submitted roster sheet, Anaheim played with 1 left wing, 1 right wing and a cast of 10 centers. On top of that, the league doesn’t distinguish between left and right defenders. It is commonly brought into question how well a defender fairs playing on their off hand, or how shallow the league’s RD depth is. Corrected position labels can settle these questions and other roster considerations. Our goal is to assigned one of the five positions to each skater observed in each game for the 2021/2022 regular season.
Data
The National Hockey League recorded the following information for every game in the 2021/2022 season:
- Players: Who played, for what team and at what position.
- Events: A list of events that occurred. Who was involved, when it happened and the integer coordinates where it took place. Note the following agent descriptors derived from the event type in bracket:
- Faceoff (Faceoff)
- Shooter (Missed Shot, Blocked Shot, Shot, Goal)
- Hitter (Hit)
- Hittee (Hit)
- Giveaway (Giveaway)
- Takeaway (Takeaway)
- Blocker (Blocked Shot)
- Shifts: Who was on the ice for each second of the game.
 x, y axes for event coordinates. From a players point of view the opposition’s net is always placed on the positive side of the x-axis.
x, y axes for event coordinates. From a players point of view the opposition’s net is always placed on the positive side of the x-axis.
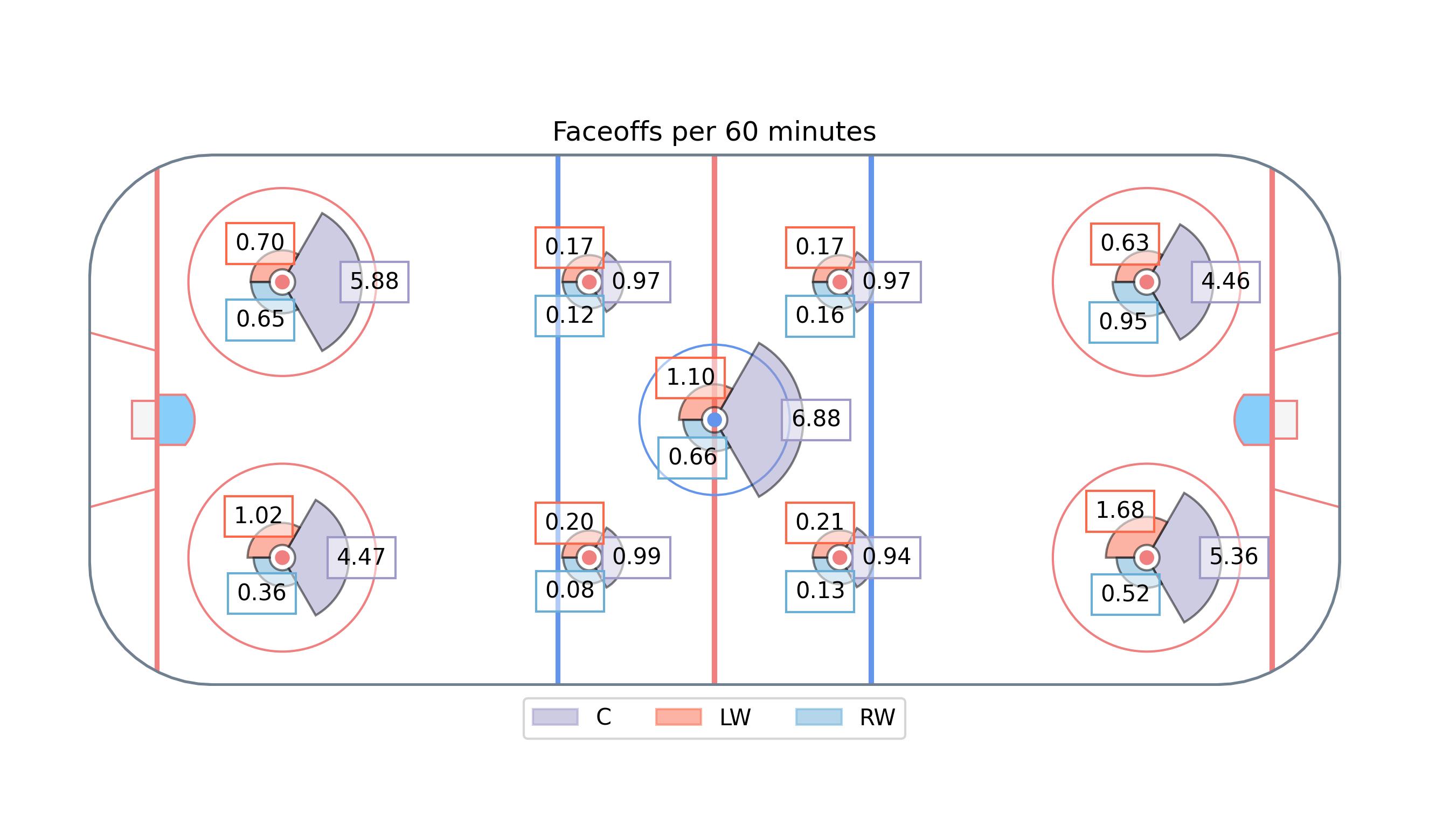
 Rates per sixty minutes for each position in the 2021/2022 season. Contour plots inspired by at IneffectiveMath on twitter
Rates per sixty minutes for each position in the 2021/2022 season. Contour plots inspired by at IneffectiveMath on twitter
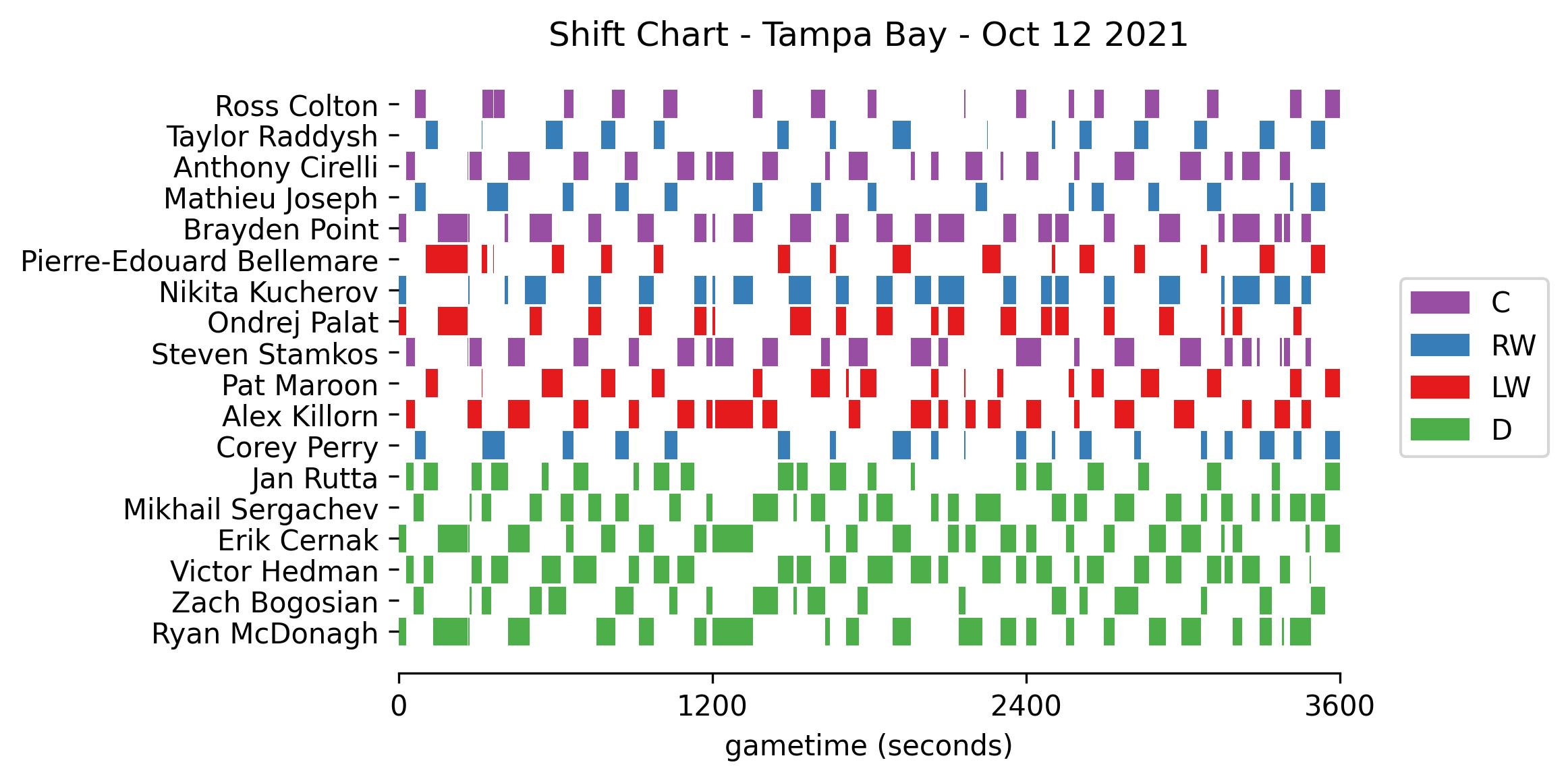 Tampa Bay’s shift data for the opening game. (gameId: 2021020001)
Tampa Bay’s shift data for the opening game. (gameId: 2021020001)
Methodology
Instead of clustering all positions at once, we take a top-down hierarchical approach. First skaters are partitioned into forwards and defenders. Then defenders into LD and RD. Then forwards into centers and wingers, and finally wingers into LW and RW.
Forwards vs. Defenders
Define the n by n matrix \(\Delta\) whose \((i, j)\)-th entry corresponds to the number of seconds teammates \(i\) and \(j\) shared on the ice at even strength in a game. The diagonal entries refer to each player’s total ice time. \(\Delta\) can be constructed using the shift data. Let \(B\) be the binary matrix obtained from the shift chart (refer to above image), then \(\Delta=BB^T\). From \(\Delta\), we compute \(\delta\) by dividing each row by its diagonal entry, so each entry refers to the proportion of a player’s time spent with another. For convenience we set the diagonal elements of \(\delta\) to zero. Each player is always accompanied by 4 teammates so every row will sum to 4. Following this thought, consider just the columns corresponding to defenders, \(\delta^D\). The sum of a forward’s row will be very close to 2; and very close to 1 for a defender. Then the binary vector \(x\) which minimizes ${i=1}^{n} | 2-x_i-^D{i}x | $ exhibits our F/D labels (\(x_i = 1\) indicating the skater is a defender). I’ve opted to solve this heuristically, via a steepest ascent local search. Neighbourhoods are defined by at most 2 label mutations from the current candidate solution. While the search is robust to choice of starting location, the provided D and F labels are quite reliable.
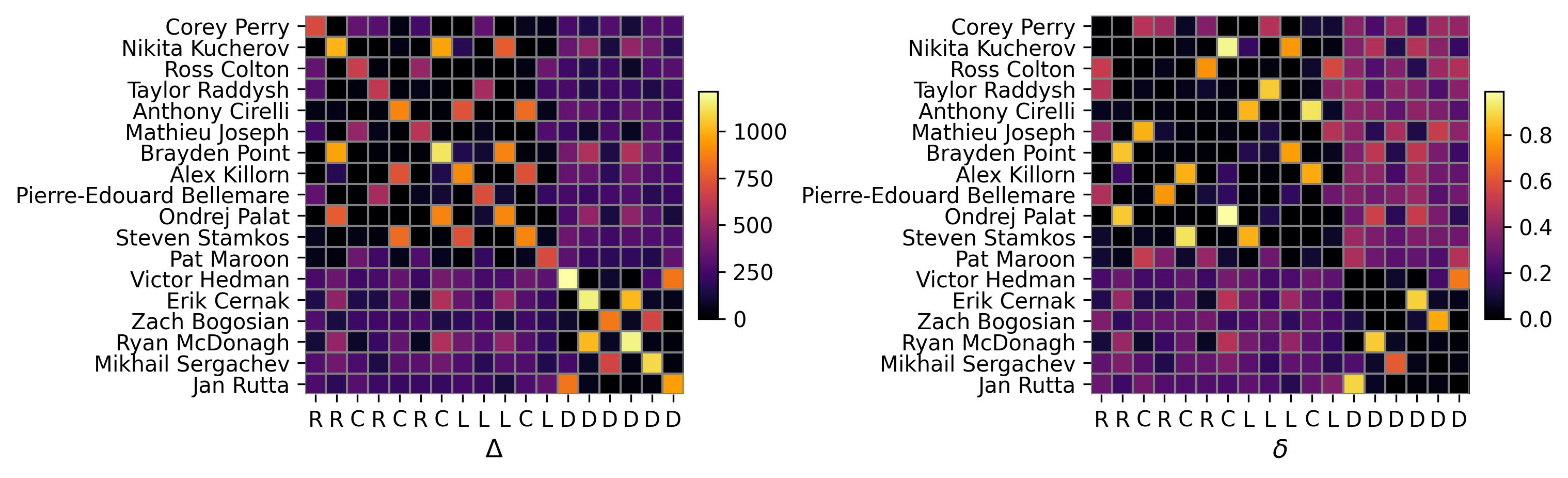 Tampa Bay’s shift data for the opening game of the 2021/2022 season presented in matrix form
Tampa Bay’s shift data for the opening game of the 2021/2022 season presented in matrix form
72 instances required swapping defenders to forwards, none in the other direction. One was the result of Robert Burtuzzo moving from D to F after the first period - caught with a row sum near 1.6. Which prompts the question, how will we handle mid game role changes? For simplicity, and issues detailed ahead, we restrict the problem to one label per player in each game.
Left vs. Right Defenders
We proceed in a similar fashion to classical expectation-maximization algorithms for mixture models. EM is an iterative algorithm that is useful for handling missing data. While defender labels are truly missing, the forwards are so messed up it’s in our best interest to treat them so.
Defenders are assigned an initial label using a biased coin, 51% in favour of whichever side of the \(y = 0\) line they appeared more often on in the game. This gentle nudge is only necessary to avoid any manual aliasing afterwards. The algorithm is described below in detail. In the next section we will adjust it to cluster the forwards.
Step 1. Naive Bayes Classifier
Let \(x_{ij}\) be a vector encoding the counts of each action \(a\) at each coordinate \((x,y)\) conducted by player \(i\) in game \(j\). For example, in the \(j\)-th game of the season, player \(i\) recorded one shot at center ice, thus \(x_{ijk}=1\) where \(k=(\text{Shooter},(0,0))\) otherwise 0. We can think of each \(x_{ijk}\) as generated independently from a poisson distribution with mean \(n_{ij}\theta_{pk}\) where \(p\) identifies the player’s position. Parameter \(\theta_{pk}\) defines the rate at which \(k\) occurs per 60 minutes. \(n_{ij}\) is the constant exposure or player \(i\)’s ice time in game \(j\) divided by 60 minutes. Then we can model the entire population of defenders as a multivariate poisson mixture with two components for LD and RD.
The conditional likelihood of \(x_{ij}\) given it has label LD is:
\[f(x_{ij} | p=LD) = \prod_{k=1}^K \frac{(n_{ij}\theta_{LD,k})^{x_{ijk}}e^{-n_{ij}\theta_{LD,k}}}{x_{ijk}!}\]
Following bayes rule the posterior likelihood is:
\[f(LD | x_{i,j}) \propto f(LD) f(x_{ij} | LD)\]
where \(f(LD)\) is the prior probability. Prior to any available information, both positions are considered to be equally likely, so \(f(RD) = f(LD) = .5\).
Finally, the log posterior odds of the two positions is:
\[ \begin{aligned} \alpha_{i,j} &= \log \frac{f(LD | x_{i,j})}{f(RD | x_{i,j})} \\ &= \sum x_{ijk} \log \frac{\theta_{LD,k}}{\theta_{RD,k}} + n_{i,j} \sum(\theta_{RD,k} - \theta_{LD,k})\\ \end{aligned} \]
which determines membership for each sub-population. A positive \(\alpha_{i,j}\) means the player is more likely to be LD.
The log odds require estimating the rate parameters, which in itself calls for existing labels. A typical solution using EM tumbles between the two calculations, with each update hopefully bringing us closer to convergence. At this point we’ve only utilized event data. A satisfying solution will pair both event and shift sources, and we address that in step 2.
Estimating the rate parameters
It can be helpful to visualize the \(\theta_{p,k}\)’s on a set of grids for each action, seen previously with the contour plots.
- For each position and action store the total counts in matrix \(M_p\), whose rows and columns coincide with the (x,y) coordinates.
Add the matrix corresponding to its mirrored position flipped along the \(y=0\) entries to \(M_p\). Add corresponding total exposure times \(N_p\) as well. \[M_{LD}'[x,y]=M_{LD}[x,y] + M_{LD}[x,-y]\]
\[N_{LD}'=N_{LD} + N_{RD}\]
- Apply a Kernel Smoothing Method to each matrix.
- Obtain the rates per 60 minutes by dividing each count by exposure \(N_{p}'\)
Step 2. Pairwise Comparisons
Due to the nature of the problem, whenever two teammates are on the ice we wish to compare them to determine who gets what label. The Bradley-Terry model is a standard approach to model pairwise comparisons. It’s commonly used in sports to model team strength from W-L records. The Davidson model is an extension to incorporate ties. Here we’ll treat winning as being assigned LD while sharing the ice with a RD. A tie refers to both players sharing the same label. The probabilities for each outcome is given as:
\[ p(i=LD, j=RD) = \frac{e^{\alpha_i}}{e^{\alpha_i}+e^{\alpha_j}+e^{z + .5(\alpha_i+\alpha_j)}}\]
\[ p(i=j) = \frac{e^{z + .5(\alpha_i+\alpha_j)}}{e^{\alpha_i}+e^{\alpha_j}+e^{z + .5(\alpha_i+\alpha_j)}}\]
\[ p(i=RD, j=LD) = \frac{e^{\alpha_j}}{e^{\alpha_i}+e^{\alpha_j}+e^{z + .5(\alpha_i+\alpha_j)}}\]
Where \(z \in (-\infty,\infty)\) determines the probability of a tie. We set \(z=0\) which seems reasonable enough for our purposes. \(\alpha_i\) represents player \(i\)’s “strength” or evidence for playing on the left side. The \(\alpha\)’s are usually fit to the response data, but for this clustering problem we take them to be the log odds computed previously. I think I’m getting away with this since both the Davidson strength terms and log odds are relative values.
Since pairwise comparisons only occur between teammates and only across one game, we can compartmentalize the labelling process accordinglyy. We find labels \(l\) such that log likelihood of our pairwise comparison model weighted by the time each pair spent on the ice is maximized:
\[ \sum_{i<j}\Delta[i,j]*log(p(i=l_i, j=l_j))\]
Furthermore, we impose a constraint on \(l\) such that the size of the majority can only surpass the minority class by 1. This enforces our expectations of roster construction. The most defenders a team has iced this season is 7; which has 70 possible configurations of LD & RD. This makes brute force is a viable option.
Step 1 and 2 are repeated until the labels converge or capped after a certain number of iterations.
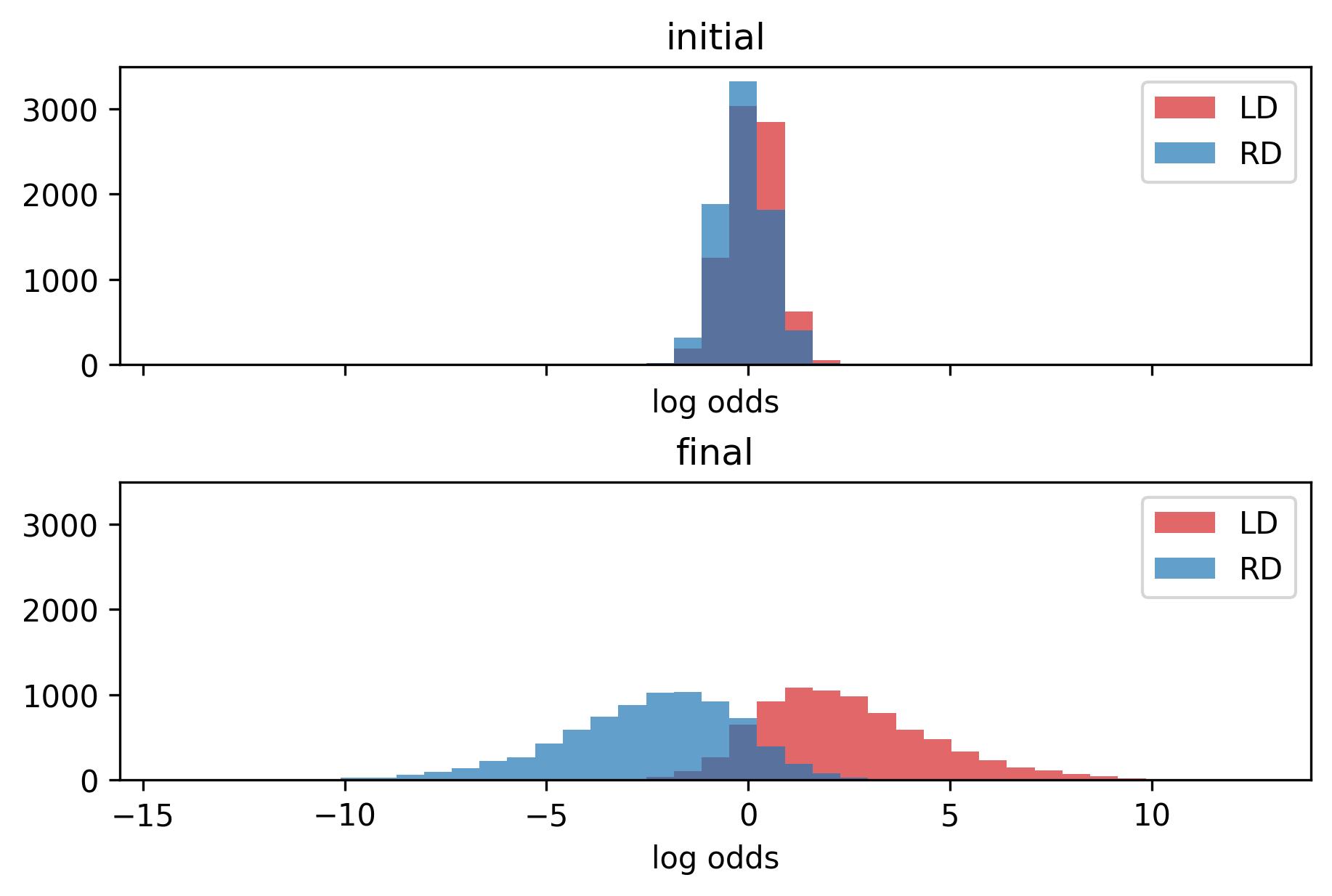 The histogram for strength terms between left and right defenders.
The histogram for strength terms between left and right defenders.
Incorporating Correlation
Event data is like splicing a video stream into snapshots of key action moments. Key moments - which might be less discriminative than the times a player is simply floating around - are rare enough a single game’s worth doesn’t ensure success. The most extreme example being Buffalo’s entire D core registering a single even strength event in (gameId: 2021020566); Boston’s Curtis Lazar was generous enough to hit Casey Fitzgerald. Conversely, events can be misleading. It’s not uncommon for players to have “off” games while their team does not provide enough to mitigate the faulty evidence.
The good news is that we don’t have to restrict ourselves to one game worth of information. It is reasonable to expect that players prefer the same roles throughout the season. Say a pair play 20 games in one orientation, how much evidence do you need to be convinced they swapped roles for the next game? To stay within our framework, I’ve decided to apply a weighted aggregate to feature vectors. Each \(x_{i,j} = \sum_{i',j'}w_{i',j'}x_{i,j}\) where \(w\) should resemble our intuition of which responses are correlated. This leads to a bevy of options. For example, a weighting can be proportional to the ice time given to the player in each game. This results in players having a constant \(\alpha\) throughout the season. It would be equivalent to a set ranking for role priority. Another option is to only weigh in games where the player spends the majority of the time with common linemates. Lines can be determined by a graph constructed from \(\delta\). Let an edge \({i,j}\) exist if \(\delta[i,j]\) and \(\delta[j,i]\) are greater than some threshold. Whittle down the threshold until you like what you see. Then all disconnected components which are triangles form F lines, all arcs form D pairs. For extra measure, restrict labels to avoid conflicts within each component.
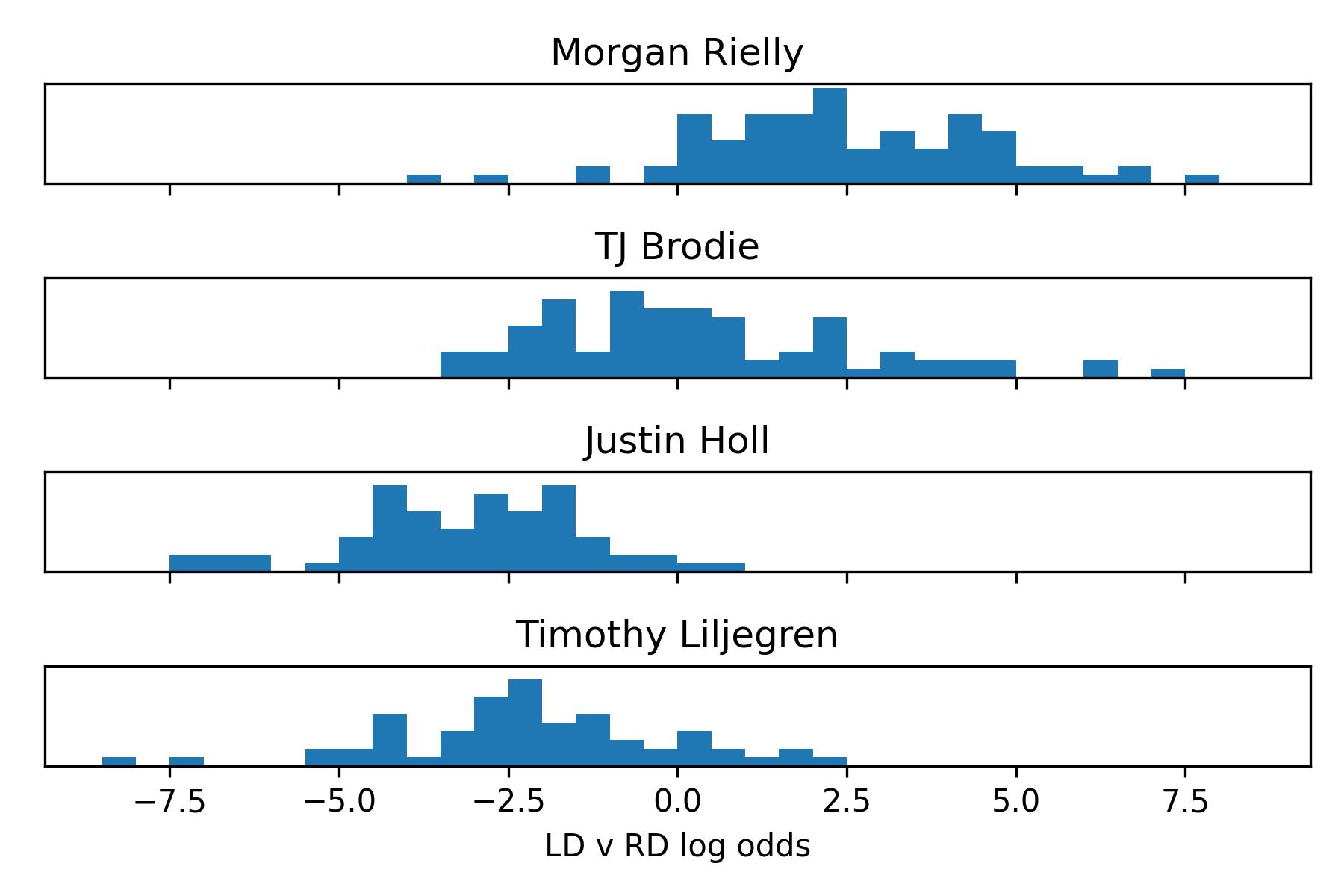 Histogram of log odds for 4 prominent members of Toronto’s Defence. Notice Morgan Rielly, who I contest played every game as LD strictly due to seniority, has some games suggesting otherwise. His partner for most of the year, TJ Brodie is flexible but indulges in the left side whenever the pair is split.
Histogram of log odds for 4 prominent members of Toronto’s Defence. Notice Morgan Rielly, who I contest played every game as LD strictly due to seniority, has some games suggesting otherwise. His partner for most of the year, TJ Brodie is flexible but indulges in the left side whenever the pair is split.
Let’s compare the results Toronto’s defence with and without aggregating. I prefer the latter, which exhibits a cleaner separation at the cost of paving over any edge cases.
| Single Game Strength | Season Strength Aggregate | Linemate Strength Aggregate | |||||
| Name | LD | RD | α | LD | RD | LD | RD |
| Jake Muzzin | 47 | 0 | 3.57 | 47 | 0 | 47 | 0 |
| Kristians Rubins | 3 | 0 | 3.3 | 3 | 0 | 3 | 0 |
| Mark Giordano | 19 | 1 | 2.97 | 20 | 0 | 19 | 1 |
| Morgan Rielly | 76 | 6 | 2.32 | 82 | 0 | 82 | 0 |
| Carl Dahlstrom | 3 | 0 | 2.07 | 3 | 0 | 3 | 0 |
| Rasmus Sandin | 43 | 8 | 1.25 | 49 | 2 | 49 | 2 |
| Travis Dermott | 23 | 20 | 0.32 | 19 | 24 | 20 | 23 |
| TJ Brodie | 28 | 54 | 0.31 | 23 | 59 | 23 | 59 |
| Ilya Lyubushkin | 2 | 29 | -1.47 | 0 | 31 | 1 | 30 |
| Timothy Liljegren | 3 | 58 | -2.08 | 0 | 61 | 0 | 61 |
| Justin Holl | 0 | 69 | -2.85 | 0 | 69 | 0 | 69 |
| Alex Biega | 0 | 2 | -3.84 | 0 | 2 | 0 | 2 |
Centers vs. Wingers
Some slight adjustments are made to accommodate forwards. At each pass of the algorithm forwards are clustered into center and winger groups, then wingers into left and right. LW and RW labels are assigned similarly to defenders. Separating out centers is a bit different and we detail the changes below.
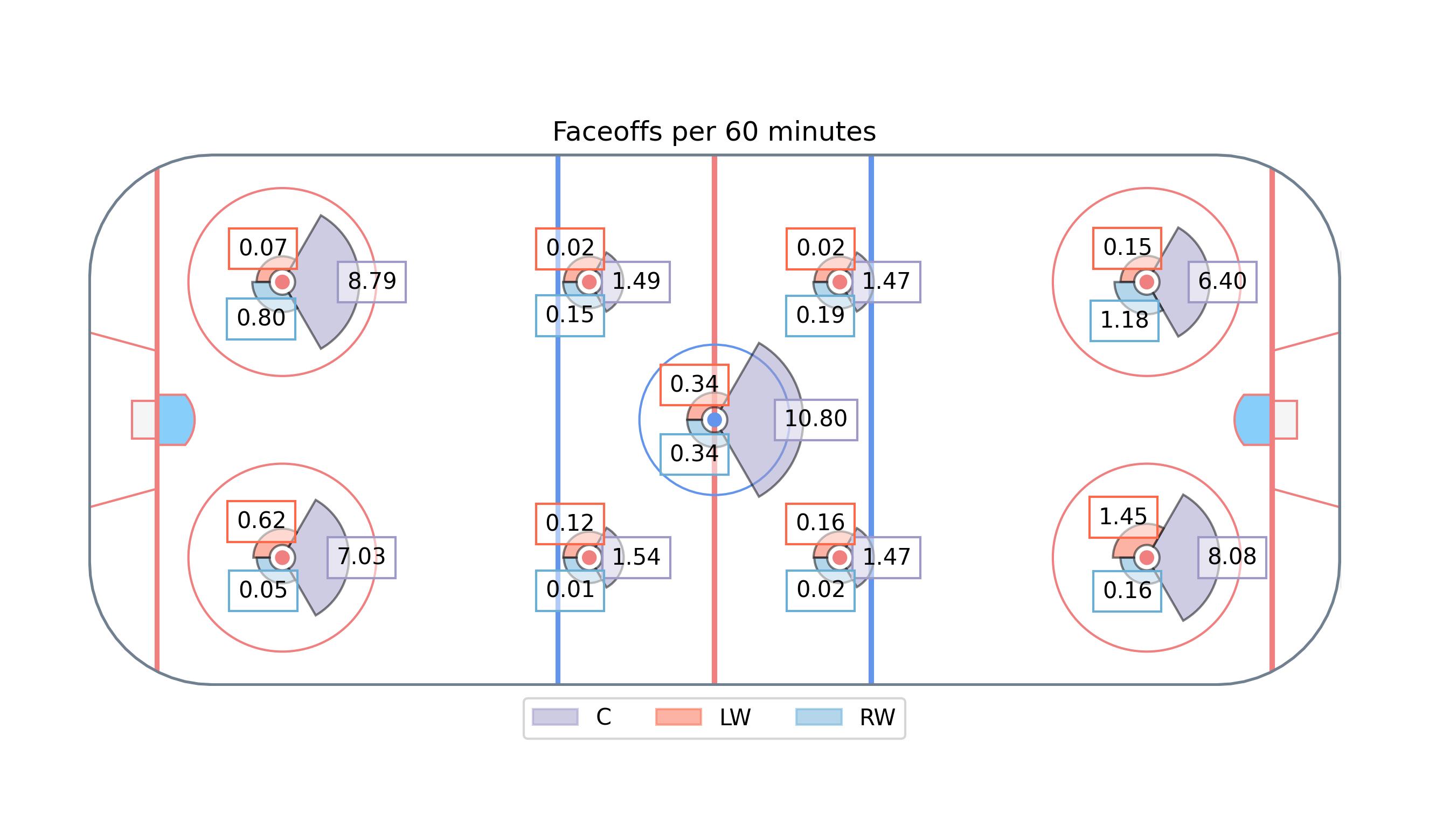
Faceoffs are included, but since they only occur in 9 locations we do not apply any KDE, though there is merit to jacking up the pseudo count to balance its effect against the other smoothed over actions.
When reflecting the counts, mirror center counts onto themselves.
Normalize the count rates for each action except Faceoffs. Essentially this creates a debt which centers can easily work out of by taking faceoffs. Thus if no actions are taken, the player is more likely to be a winger.
Calculate the log odds between center and the two winger classes as:
\[\begin{aligned} \beta_{i,j} &= log \frac{f(C | x_{i,j})}{f(LW | x_{i,j})+f(RW | x_{i,j})} \\ &= log\frac{\prod e^{-n_{i,j}\theta_{C,k}}(n_{i,j}\theta_{C,k})^{x_ijk}}{\prod e^{-n_{i,j}\theta_{LW,k}}(n_{i,j}\theta_{LW,k})^{x_ijk} + \prod e^{-n_{i,j}\theta_{RW,k}}(n_{i,j}\theta_{RW,k})^{x_ijk}}\\ &= \sum x_{ijk}log \theta_{C,k} - n_{i,j} \sum\theta_{C,k} - log (\prod e^{-n_{i,j}\theta_{LW,k}}\theta_{LW,k}^{x_ijk} + \prod e^{-n_{i,j}\theta_{RW,k}}\theta_{RW,k}^{x_ijk})\\ &= \sum x_{ijk}log \theta_{C,k} - n_{i,j} \sum\theta_{C,k} - log (\prod e^{-n_{i,j}\theta_{LW,k}}(\prod\theta_{LW,k}^{x_ijk} + \prod\theta_{RW,k}^{x_ijk}))\\ &= \sum x_{ijk}log \theta_{C,k} - n_{i,j} \sum(\theta_{C,\text{Faceoffs}} - \theta_{LW,\text{Faceoffs}}) - log (e^{\sum x_{ijk}log \theta_{LW,k}} + e^{\sum x_{ijk}log \theta_{RW,k}})\\ \end{aligned} \]
Calculate the log likelihood using the Davidson-Luce Model for groupwise comparisons [1]. Compare every combination of three forwards. Once again weigh by shared ice time. Limit the amount of C labels assigned in one game between \(\lfloor \frac{\text{\# of forwards}}{3}\rfloor\) and \(\lceil \frac{\text{\# of forwards}}{3}\rceil\).
- \[ p(l_i=C, l_j=W, l_k=W) \propto e^{\beta_i}\]
- \[ p(l_i=W, l_j=C, l_k=W) \propto e^{\beta_j}\]
- \[ p(l_i=W, l_j=W, l_k=C) \propto e^{\beta_k}\]
- \[ p(l_i=C, l_j=C, l_k=W) \propto e^{z_2 + \frac{1}{2}(\beta_i + \beta_j)}\]
- \[ p(l_i=C, l_j=W, l_k=C) \propto e^{z_2 + \frac{1}{2}(\beta_i + \beta_k)}\]
- \[ p(l_i=W, l_j=C, l_k=C) \propto e^{z_2 + \frac{1}{2}(\beta_j + \beta_k)}\]
- \[ p(l_i=W, l_j=W, l_k=W) \propto e^{z_3 + \frac{1}{3}(\beta_i + \beta_j + \beta_k)}\]
- \[ p(l_i=C, l_j=C, l_k=C) \propto e^{z_3 + \frac{1}{3}(\beta_i + \beta_j + \beta_k)}\]
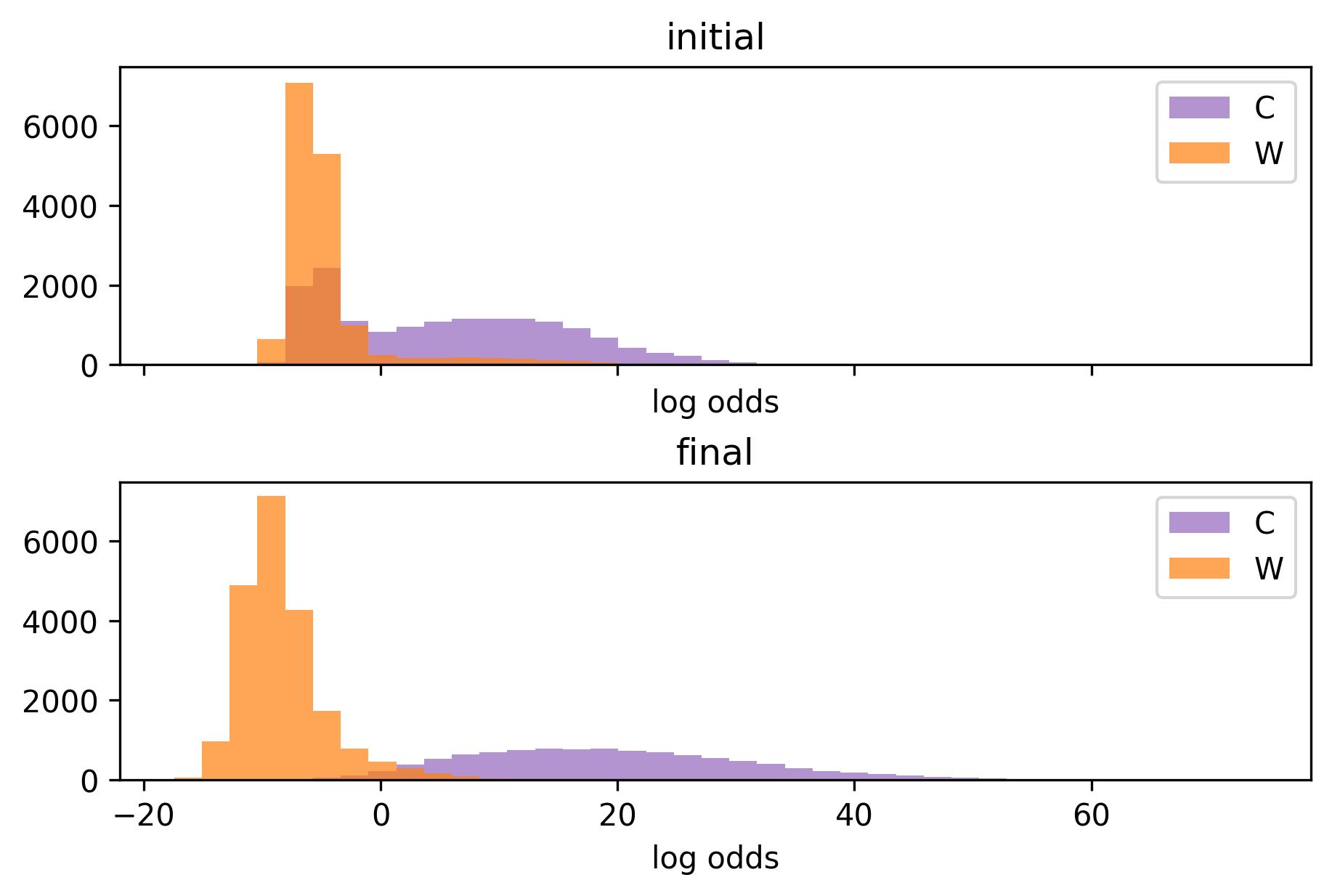 The histogram for log odds between center and winger. The mixture clearly exhibits two components, it’s easy to spot the pretenders immediately. The final distribution for centers is wide due to the weight of faceoffs. Modelling faceoff rates as a poisson distribution may not be the best choice, since coaches try to allocate them based on preference.
The histogram for log odds between center and winger. The mixture clearly exhibits two components, it’s easy to spot the pretenders immediately. The final distribution for centers is wide due to the weight of faceoffs. Modelling faceoff rates as a poisson distribution may not be the best choice, since coaches try to allocate them based on preference.
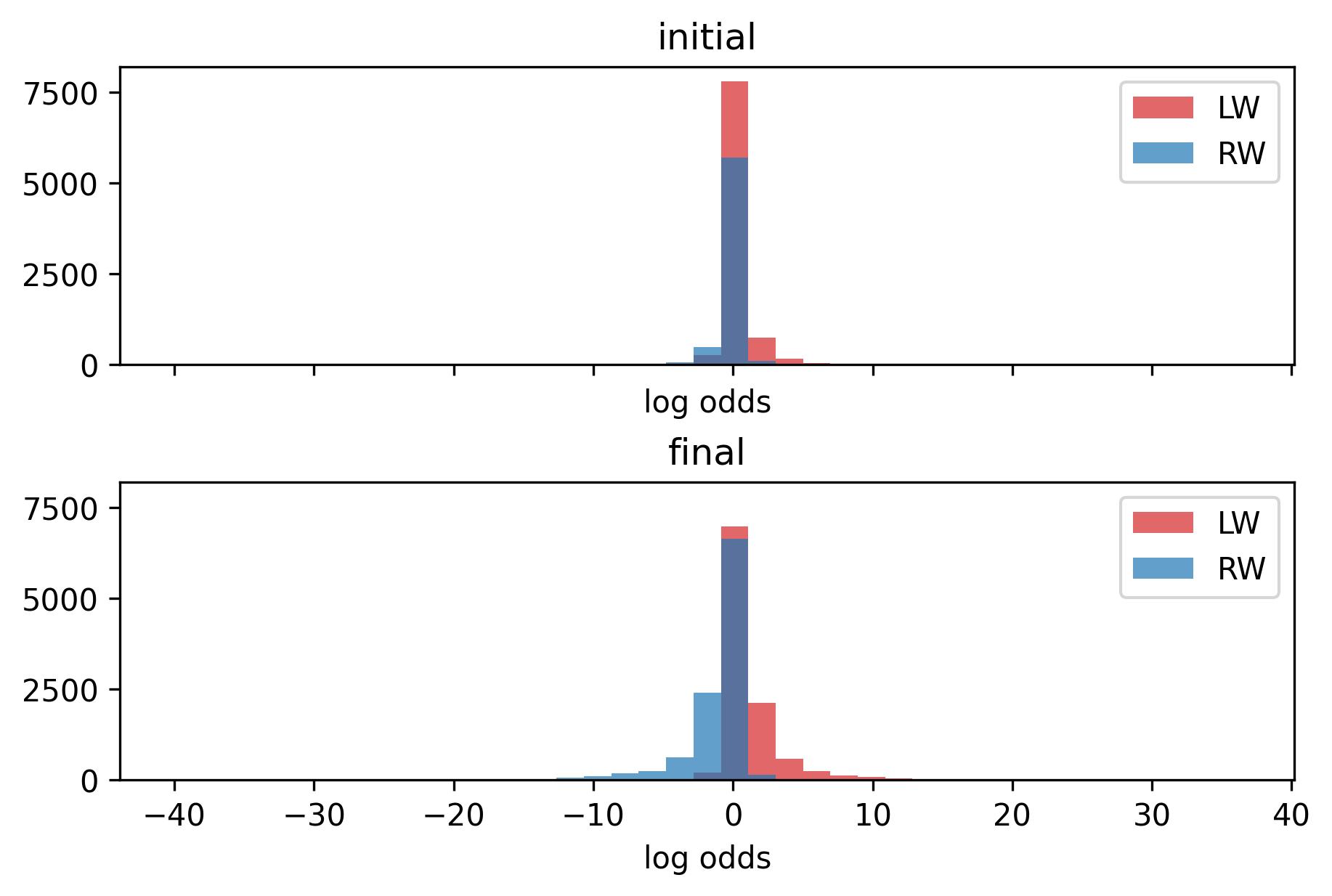 The histogram for log odds between left and right wingers, a sad site.
The histogram for log odds between left and right wingers, a sad site.
Once again, let’s look at the results for Toronto. The winger labels are suspect until we aggregate games. Season and linemate weightings tend to agree. When they do not, manual inspection typically favours the latter when the line has played plenty of games together.
| Single Game Strength | Season Strength Aggregrate | Linemate Strength Aggregrate | |||||||||
| Name | C | LW | RW | Β | α | C | LW | RW | C | LW | RW |
| Auston Matthews | 73 | 0 | 0 | 27.57 | 2.47 | 73 | 0 | 0 | 73 | 0 | 0 |
| John Tavares | 79 | 0 | 0 | 22.8 | 1.01 | 79 | 0 | 0 | 79 | 0 | 0 |
| David Kampf | 82 | 0 | 0 | 19.31 | 0.95 | 82 | 0 | 0 | 82 | 0 | 0 |
| Jason Spezza | 61 | 1 | 9 | 9.54 | -2.61 | 70 | 0 | 1 | 62 | 3 | 6 |
| Brett Seney | 2 | 0 | 0 | 0.55 | 1.72 | 1 | 1 | 0 | 2 | 0 | 0 |
| Colin Blackwell | 11 | 0 | 8 | -3.1 | -1.58 | 5 | 0 | 14 | 9 | 0 | 10 |
| Nicholas Abruzzese | 1 | 5 | 3 | -4.95 | 0.03 | 1 | 7 | 1 | 1 | 6 | 2 |
| Kirill Semyonov | 1 | 1 | 1 | -5.77 | 0.28 | 0 | 3 | 0 | 1 | 1 | 1 |
| Alexander Kerfoot | 12 | 53 | 17 | -6.24 | 0.7 | 10 | 72 | 0 | 12 | 54 | 16 |
| Alex Steeves | 0 | 0 | 3 | -6.31 | -0.27 | 2 | 0 | 1 | 0 | 0 | 3 |
| Michael Amadio | 0 | 1 | 2 | -6.35 | -0.99 | 0 | 0 | 3 | 0 | 3 | 0 |
| Kyle Clifford | 1 | 15 | 7 | -6.73 | 0.22 | 3 | 15 | 5 | 1 | 19 | 3 |
| Wayne Simmonds | 0 | 31 | 41 | -7.51 | -0.23 | 1 | 11 | 60 | 0 | 9 | 63 |
| Pierre Engvall | 4 | 43 | 31 | -7.94 | 0.17 | 0 | 59 | 19 | 4 | 44 | 30 |
| Nicholas Robertson | 0 | 7 | 3 | -7.99 | -0.04 | 0 | 8 | 2 | 0 | 9 | 1 |
| Joey Anderson | 0 | 1 | 4 | -8.13 | -0.19 | 0 | 0 | 5 | 0 | 0 | 5 |
| Nick Ritchie | 0 | 25 | 8 | -8.94 | 0.48 | 0 | 33 | 0 | 0 | 33 | 0 |
| Ondrej Kase | 0 | 11 | 39 | -9.21 | -0.41 | 0 | 3 | 47 | 0 | 2 | 48 |
| William Nylander | 1 | 26 | 54 | -9.34 | -0.54 | 0 | 0 | 81 | 1 | 16 | 64 |
| Ilya Mikheyev | 0 | 35 | 18 | -9.82 | 0.25 | 0 | 38 | 15 | 0 | 52 | 1 |
| Michael Bunting | 0 | 51 | 28 | -10.72 | 0.21 | 0 | 77 | 2 | 0 | 76 | 3 |
| Mitchell Marner | 0 | 21 | 51 | -11.3 | -0.18 | 0 | 1 | 71 | 0 | 0 | 72 |
As for the entire league, 36229 out of 47208 come to a concensus for all three options. The remaining conflicts are resolved in the following manner. First by majority vote, then by sorting out the remaining labels for each game and team with the single game strength terms.
Concluding Remarks
There remains a lot to be tinkered with. Adding penalties, separating wrap-arounds or other secondary types from shots, partitioning the rink’s grid by zone before smoothing, possibly some more denoising… I suspect most to be fruitless. The main sticking point is distilling winger labels. Diminishing the additive smoothing or pushing the KDE to produce more discriminative ratios leads to similar yet murky results. Forwards tend to cross over the \(y = 0\) line enough to require more spatial sampling for consistency. The only way I’ve found to overcome this is by feeding season data into the single game strength terms, in perhaps the most unprincipled manner (please feel free to lecture me on my bad behaviour). I subsist this provides close to ideal results without manual inspection. It seems adequate if your goal is to get positional eligibility status for fantasy hockey. Keep scrolling down for results.
You can reach me on twitter at yimmymcbill if you have suggestions, there is certainly room for improvement!
I’ve provided a summary for each team in the links below.
Anaheim Ducks Arizona Coyotes Boston Bruins Buffalo Sabres Calgary Flames Carolina Hurricanes Chicago Blackhawks Colorado Avalanche Columbus Blue Jackets Dallas Stars Detroit Red Wings Edmonton Oilers Florida Panthers Los Angeles Kings Minnesota Wild Montréal Canadiens Nashville Predators New Jersey Devils New York Islanders New York Rangers Ottawa Senators Philadelphia Flyers Pittsburgh Penguins San Jose Sharks Seattle Kraken St. Louis Blues Tampa Bay Lightning Toronto Maple Leafs Vancouver Canucks Vegas Golden Knights Washington Capitals Winnipeg Jets
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
References
[1] Firth, D., Kosmidis, I., & Turner, H. (2019). Davidson-Luce model for multi-item choice with ties. arXiv preprint arXiv:1909.07123.
Defender Results
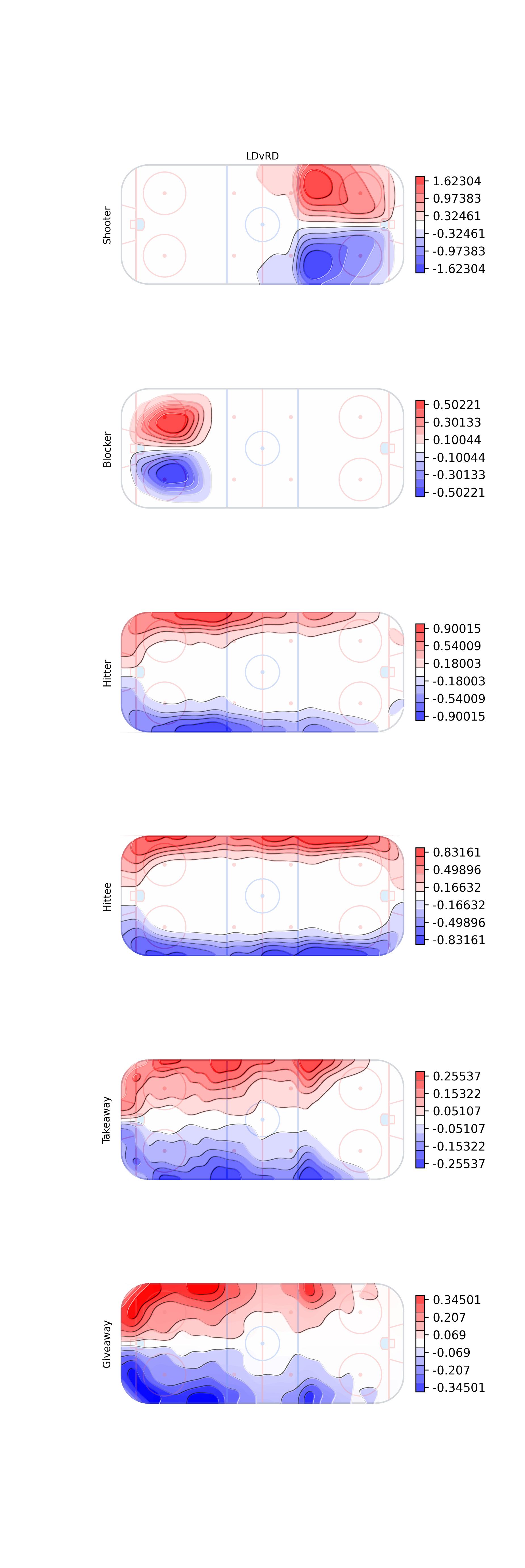 The final estimates for the coefficient-like terms for the event counts in the posterior odds ratio formula. The log of the LD over RD rate parameters.
The final estimates for the coefficient-like terms for the event counts in the posterior odds ratio formula. The log of the LD over RD rate parameters.
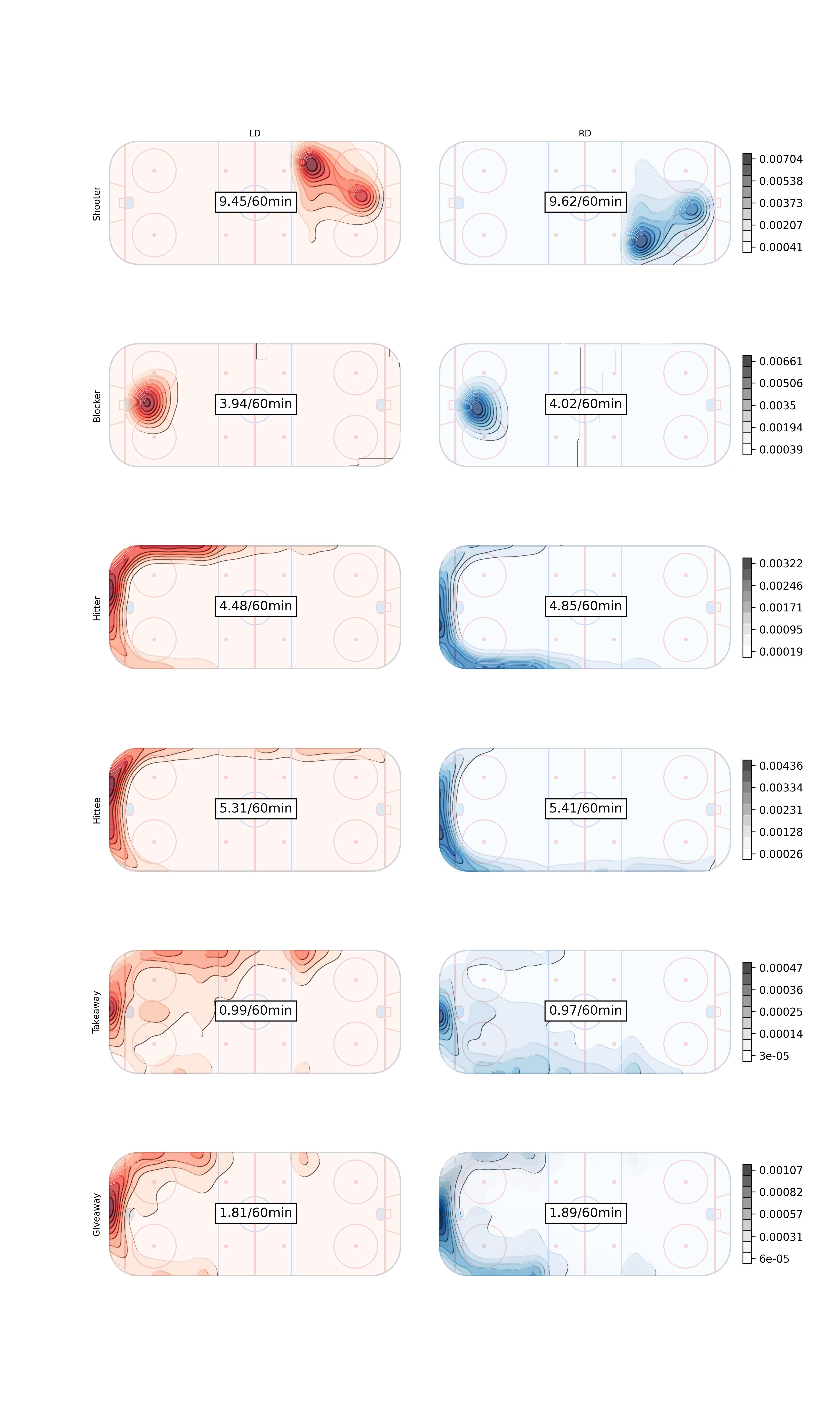 The final Rates per sixty minutes for left and right defenders
The final Rates per sixty minutes for left and right defenders
Forward Results
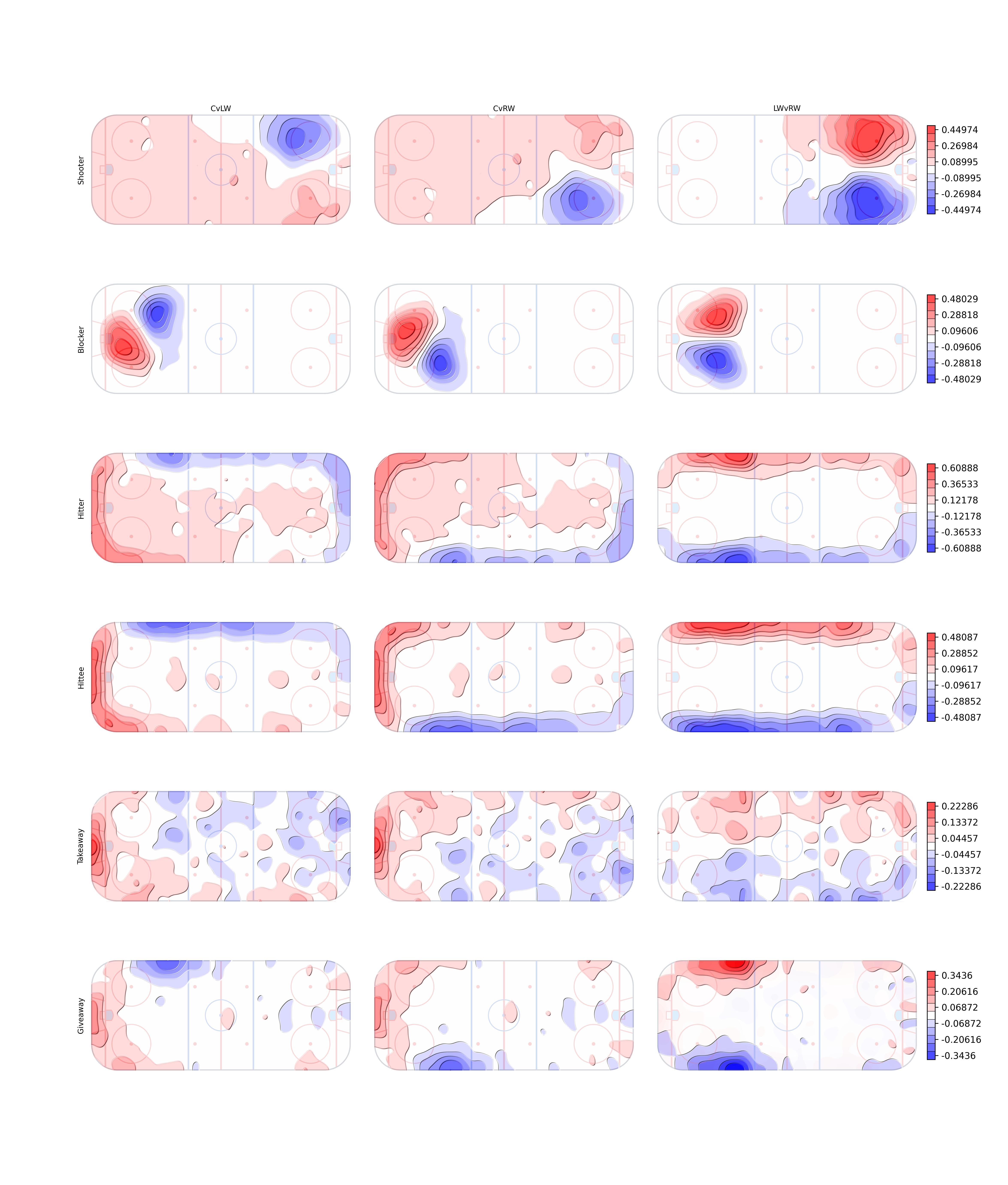 The final estimates for the coefficient-like terms for the event counts in the posterior odds ratio formula between two of the three forward positions.
The final estimates for the coefficient-like terms for the event counts in the posterior odds ratio formula between two of the three forward positions.
 An example using Gaussian KDE with \(\sigma\) cranking up to 20.
An example using Gaussian KDE with \(\sigma\) cranking up to 20.
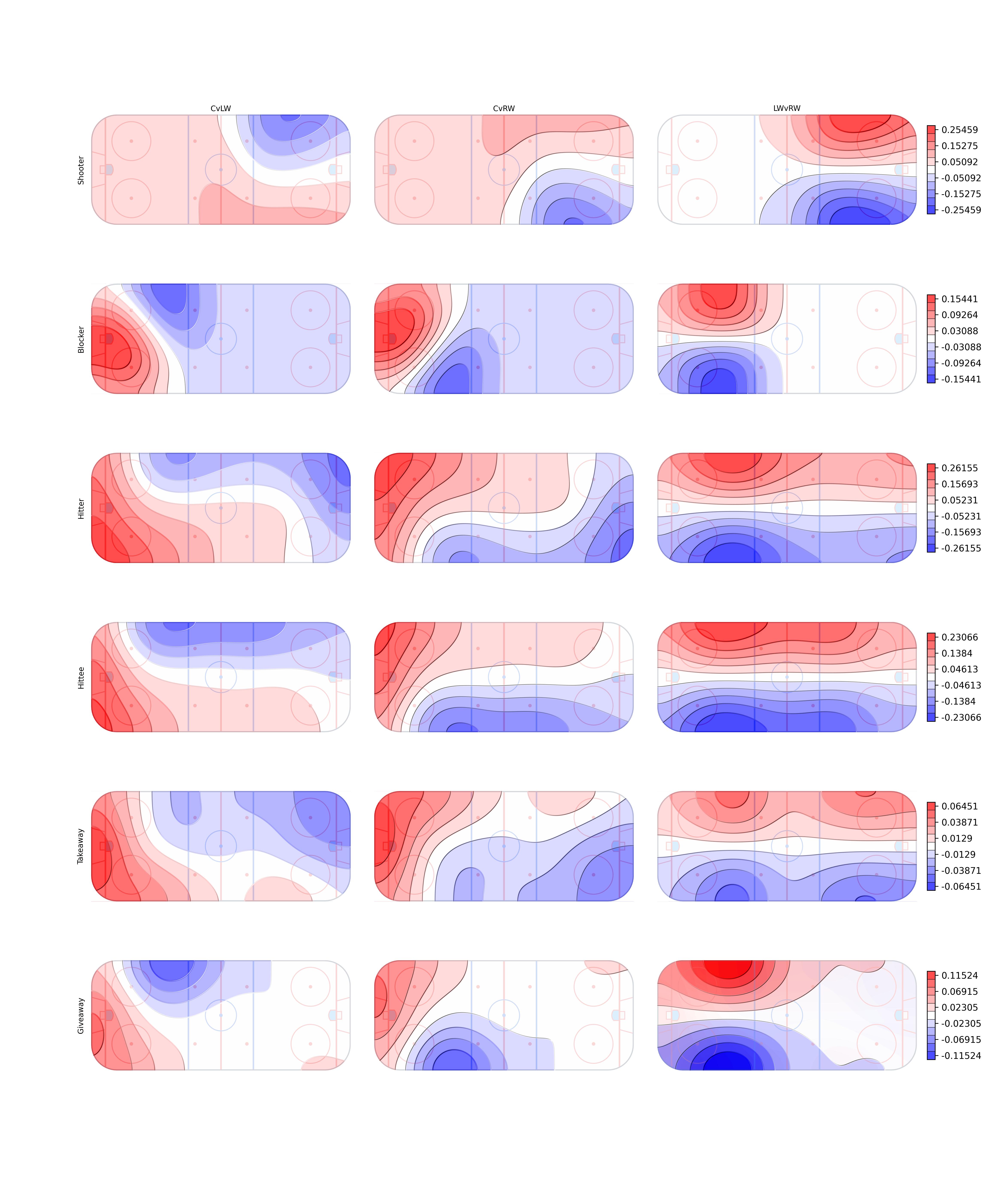
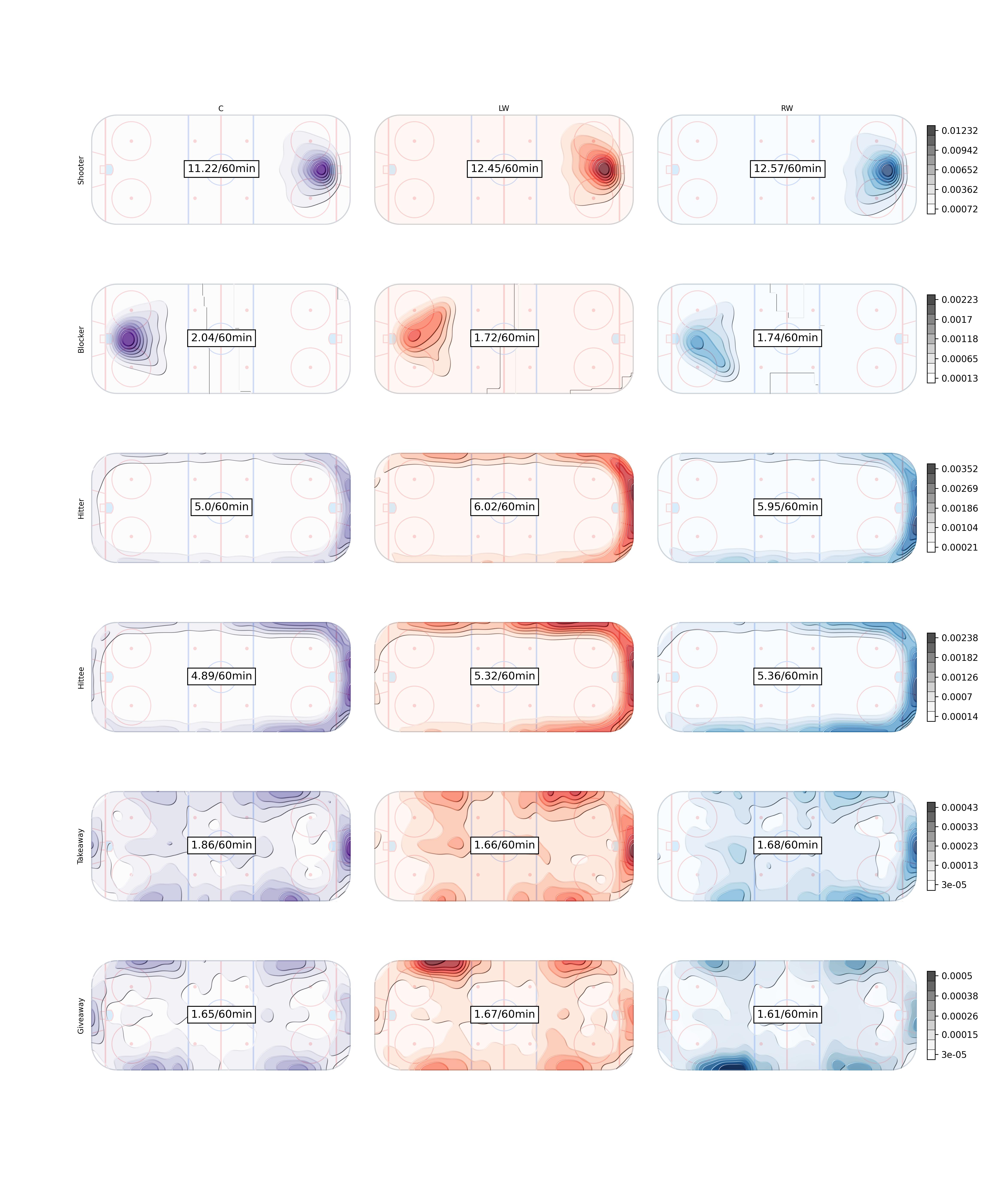 The final Rates per sixty minutes for all forward positions
The final Rates per sixty minutes for all forward positions
Forwards Labelled as Defenders
| playerId | fullName | gameId |
|---|---|---|
| 8474145 | Robert Bortuzzo | 2021020311 |
| 8474722 | Luke Witkowski | 2021020939 |
| 8475625 | Matt Irwin | 2021020469 |
| 8476372 | Nick Seeler | 2021020739 |
| 8476470 | Nathan Beaulieu | 2021020314 |
| 8476779 | Brad Hunt | 2021021152 |
| 8477073 | Kurtis MacDermid | 2021020299, 2021020321, 2021020399, 2021020415, 2021020433, 2021020490, 2021020580, 2021020591, 2021020606, 2021020622, 2021020634, 2021020641, 2021020663, 2021020805, 2021020826, 2021020836, 2021020857, 2021020871, 2021020886, 2021020962, 2021020982, 2021021119 |
| 8477335 | Kyle Burroughs | 2021021175, 2021021192 |
| 8477419 | Mason Geertsen | 2021020043, 2021020056, 2021020090, 2021020226, 2021020327, 2021020360, 2021020422, 2021020529, 2021020586, 2021020631, 2021020666, 2021020817, 2021020875, 2021020904, 2021020921, 2021020935, 2021020966, 2021020989, 2021021005, 2021021074, 2021021274 |
| 8477851 | Jordan Oesterle | 2021020472, 2021021101, 2021021222, 2021021235 |
| 8477938 | Haydn Fleury | 2021020967 |
| 8478013 | Jake Walman | 2021020394, 2021020547 |
| 8478017 | Mark Friedman | 2021021029 |
| 8479372 | Josh Mahura | 2021020907 |
| 8479376 | Victor Mete | 2021021199 |
| 8479439 | Jacob MacDonald | 2021020105, 2021020122, 2021020145 |
| 8479639 | Dylan Coghlan | 2021021073, 2021021126 |
| 8480160 | Radim Simek | 2021021171 |
| 8480884 | Calen Addison | 2021020344, 2021020599 |
| 8481003 | Hunter Drew | 2021021285, 2021021307 |
| 8482624 | Daniil Miromanov | 2021020100 |